AI-Driven Product Design
AI Insights: turning plain-English questions into dashboards people trust
How a working knowledge of the natural-language-to-SQL pipeline, paired with rigorous user research, unlocked a +35% lift in weekly active use inside Renaissance Member Central.
My Role
Lead UX / Product Designer
Timeline
4 Months (2026)
Core Tech Stack
Azure OpenAI, NL-to-SQL, Schema-Grounded Prompting, Angular / RAIS
Key Outcome
+35% Weekly Active Use
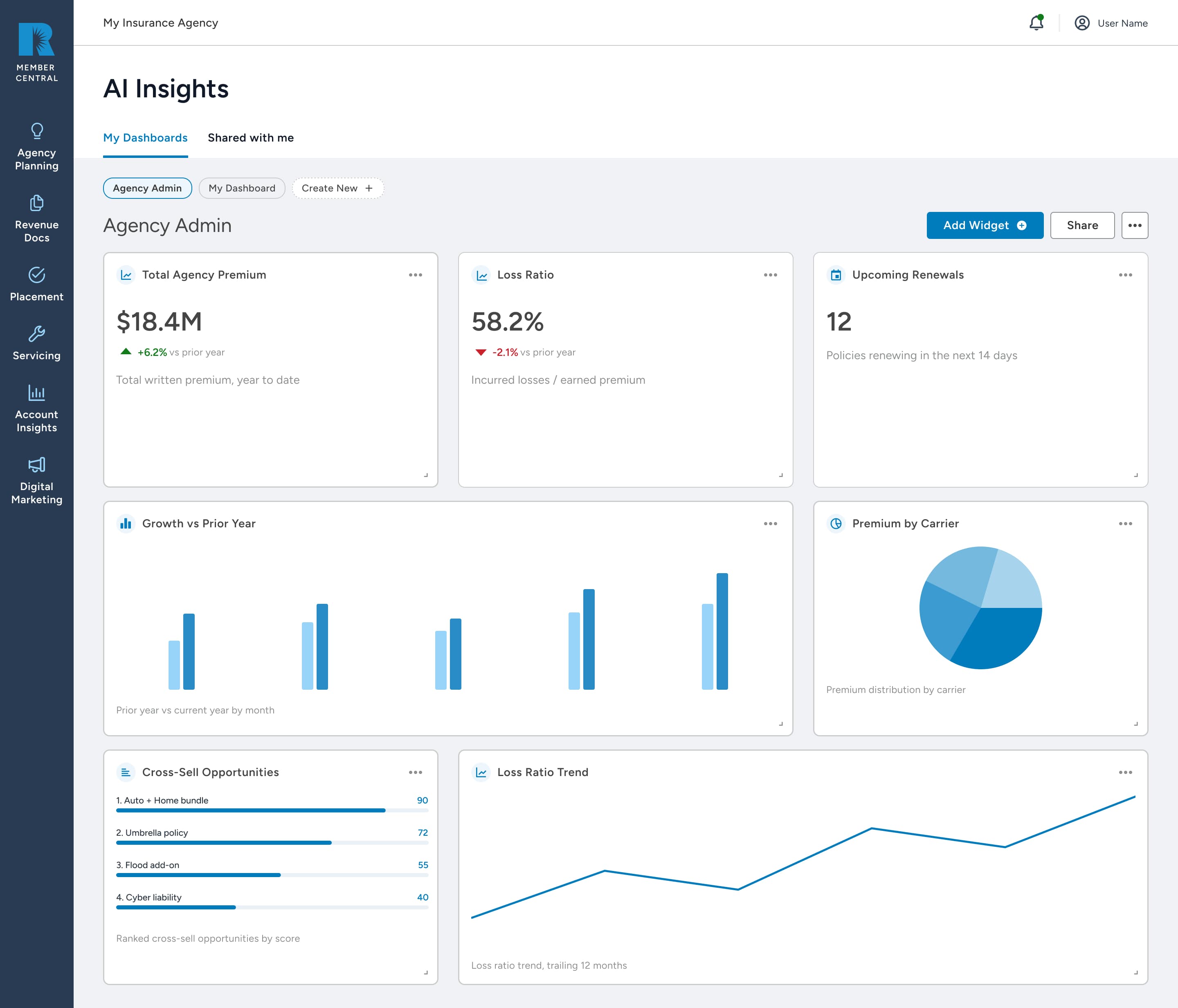
Executive Summary & Impact
The Challenge
Member Central holds the data insurance agencies live on: premium, loss ratios, retention, carrier mix, renewals. Reaching it meant requesting a report, waiting on an analyst, or living inside fixed dashboards. The team wanted an AI layer that answered questions directly, but an LLM that can be wrong is a trust problem before it is a feature.
The Strategy
I bridged the engine and the user's mental model. The model only translates English into a governed SQL query, so I built the experience around that fact: an invisible AI, a single source of truth shared with the rest of the product, and explicit, deterministic response states that turn the model's limits into guidance instead of dead ends.
Weekly active use of the Insights section after launch
Replace with measuredPerceived speed in testing once generation showed its progress
Replace with measuredPositive feedback on trusting the numbers it returned
Replace with measuredDeep User Research & Mental Models
I ran a discovery phase with internal Growth Advisors and Member Success Partners, then validated against the field with 15 interviews across external agency producers, admins, and service staff. The finding was consistent: users were not rejecting AI for lack of capability. They rejected it for lack of trust and predictability.
The Black Box Paradox
People felt anxious clicking Generate without knowing what data the model would touch, or whether the answer was the real numbers or an "AI version" of them.
The Cost of a Wrong Number
In insurance, one wrong-looking figure discredits the whole tool. Distrusting an answer costs more time than the old manual report ever did.
They Think in Questions, Not Charts
Nobody asked for a grouped bar chart. They asked "how am I doing versus last year" and expected the tool to choose the right view.
Saving Is the Real Job
The first answer is nice. The recurring value is pinning the answers that matter into a dashboard they open every Monday.
Technical Constraints & AI Orchestration Know-How
A great AI designer does not just sketch perfect states. They design for the edge cases of the engine. I mapped the pipeline with engineering first: a question goes to a NestJS backend that wraps it in a schema manifest of nine approved tables, Azure OpenAI returns a single SQL SELECT, and a validator rejects anything that is not a clean read scoped to the user's own agency. Then the interface mechanics were drawn to match.
Slow, and sometimes wrong
Generation could take several seconds while the model wrote SQL, the validator checked it, and the query ran. Worse, the question could be ambiguous, the data unavailable, or not a data question at all.
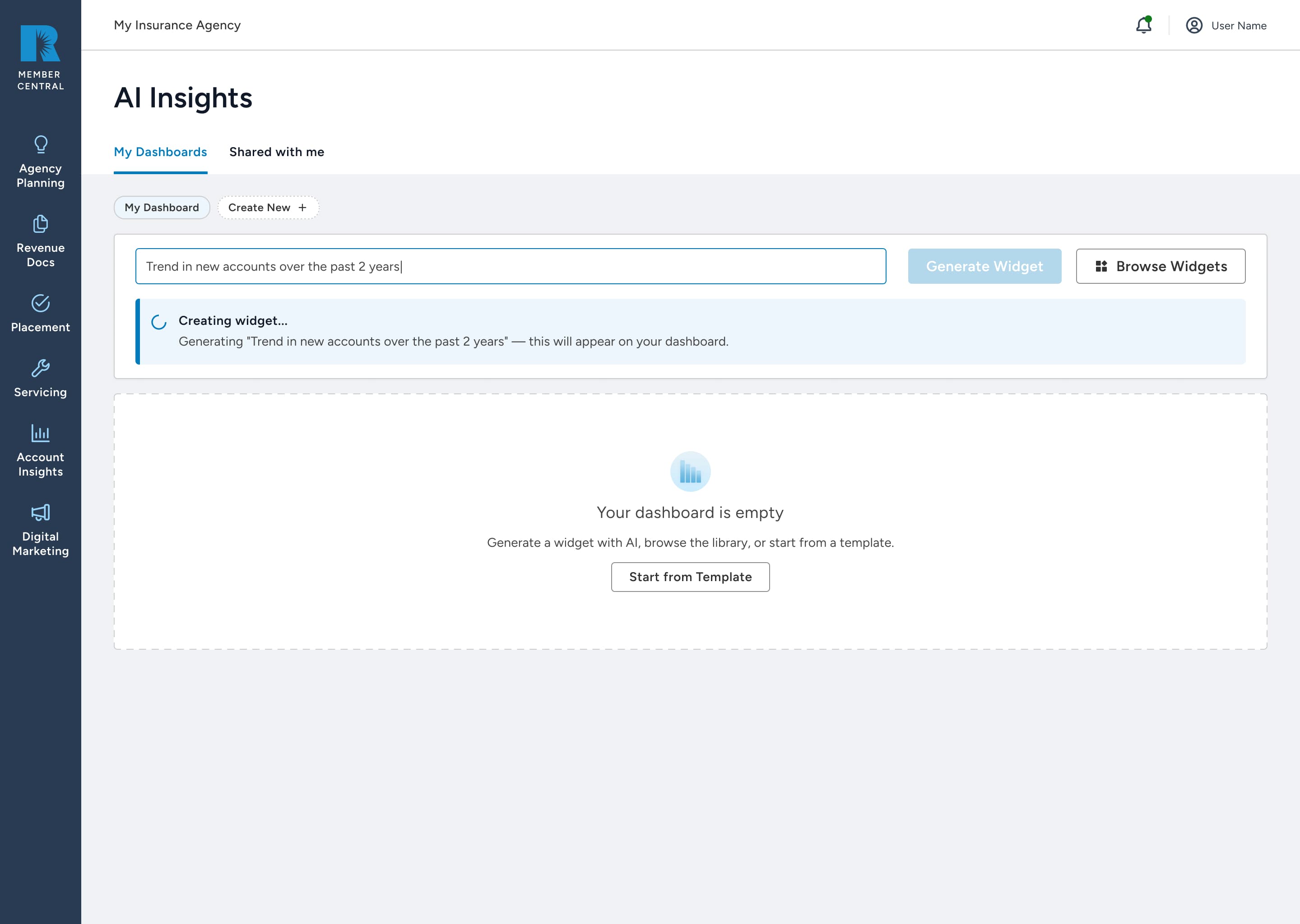
A response state for every outcome
Instead of a spinner and a generic error, I designed a five-state response system. The wait shows what is being built, and each failure mode becomes a focused, recoverable next step in the product's own voice.
Success
Needs clarification
Partial match
Unsupported data
Not a data request
Iterative Usability Testing & Validation
I ran two phases of moderated testing with 10 external users on interactive prototypes, to validate whether the response framework actually mitigated distrust.
Silent guess vs. one question
Early on the system made a best guess on ambiguous prompts. Watching people quietly distrust a grouping they never asked for, I made the one-question clarification the default. Perceived competence jumped, even though the engine was unchanged.
Confidence and verification
Users wanted proof the number was real. I added plain captions that name the data and tie each widget visibly to the same source of truth as the rest of Member Central, so the answer reads as Member Central data, not "AI data."
The Outcome: Adoption & Trust
The feature became sticky because it treats the user as the person in control, not a passive observer waiting on a black box. People ask in their own words, get an answer that matches the rest of their data, and keep the ones that matter.
For the first time I'm not second-guessing the tool. It asks what I mean when it's not sure, and the numbers match what I already see in Member Central, so I just trust it.
Agency Admin, external user testing
Takeaways for hiring managers